


Gopher, one of the early rivals of Tim Berners-Lee’s World Wide Web for storing and indexing data, was once a legitimate competitor in the struggle toward establishing a de facto standard for using the Internet. But we don’t talk about “digging in Gopherspace” anymore–instead, we “browse the web.”
So, what happened to Gopher? How did this promising protocol become all but obsolete?
It’s easy to assume that the web and the Internet are the same thing. But they aren’t: The web is a “protocol” that works over the Internet, a language that your web browser and a web server (and other programs) use to communicate and exchange data. These programs talk using a standard called the HyperText Transfer Protocol (HTTP)–only one of a number of protocols developed when the Internet first became popular in the early 1990s to make storing, accessing, and connecting data easier as more and more computers connected to the growing network.
A group from the University of Minnesota first developed Gopher, releasing it in 1991 as RFC 1436. (A Request for Comment–a standard way of releasing new protocols for use on the Internet). Gopher was then described as “software following a simple protocol for burrowing through a TCP/IP Internet.” The name came from the University of Minnesota football team, nicknamed the Golden Gophers after the ubiquitous, burrowing mammal that lives in the state.
The developers also released the first version of the Gopher server, allowing anyone to set one up–and since it was so easy to do, they quickly became popular. A couple of years later, finding data on Gopher became easier with the release of Veronica and Jughead, search engines that crawled and indexed Gopher servers much like Google does for websites.
Simplicity and structure were key elements of Gopher: A user browsed it as a series of menus and either clicked on links or entered a text response to a menu. Information was categorized into a number of different types, defined by a number or letter, which told the reader what was coming next–if it was plain text, an image, or a link to another Gopher page.
Looking around Gopherspace is a little different to browsing the web. Here’s a typical Gopher session, using Gopher Client, written by Matjaž MeÅ¡njak:
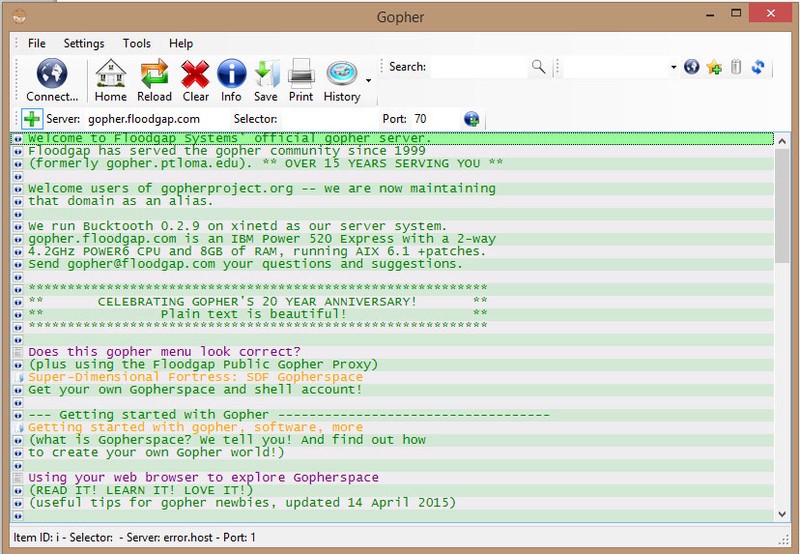
The Gopher client takes us to our home page, a Gopher server run by Floodgap. The text is the Gopher menu, or the information we are browsing. We navigate using the directional keys, and an icon indicating item type precedes each line. The client here translates the number or letter for the item type into an icon, such as the “i” for plain text. An arrow means it’s a link to another page. Let’s take a look at one by scrolling down to “Getting started with Gopher” and hitting enter.
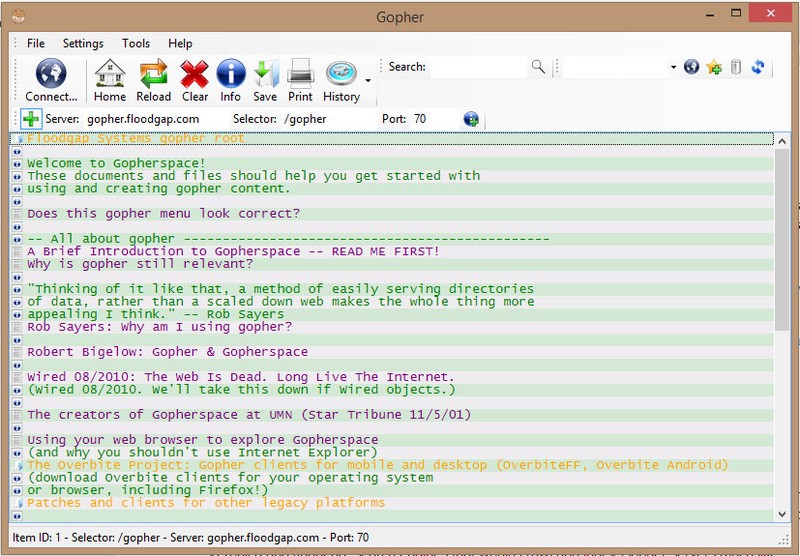
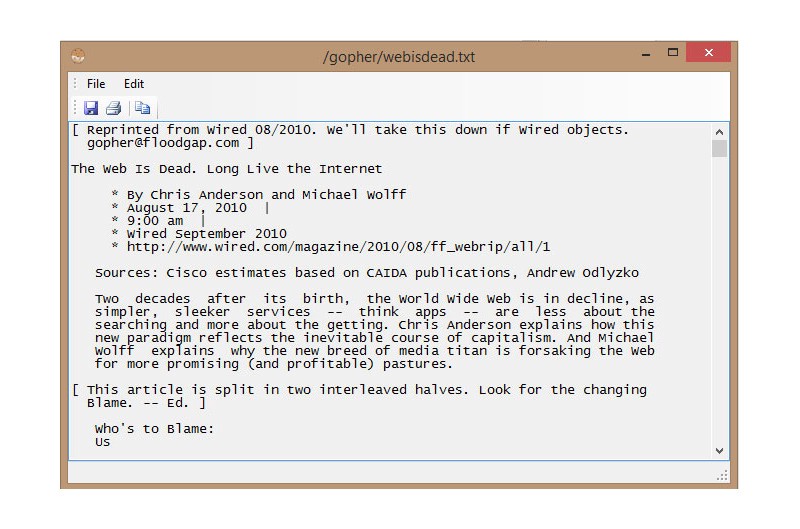
This takes us to another page, which offers more information about using Gopher, as well as a link to a Wired article from 2010. Let’s take a look at that–the text pops up in a new window:
Now, let’s do a search on Veronica, a Gopherspace search engine.
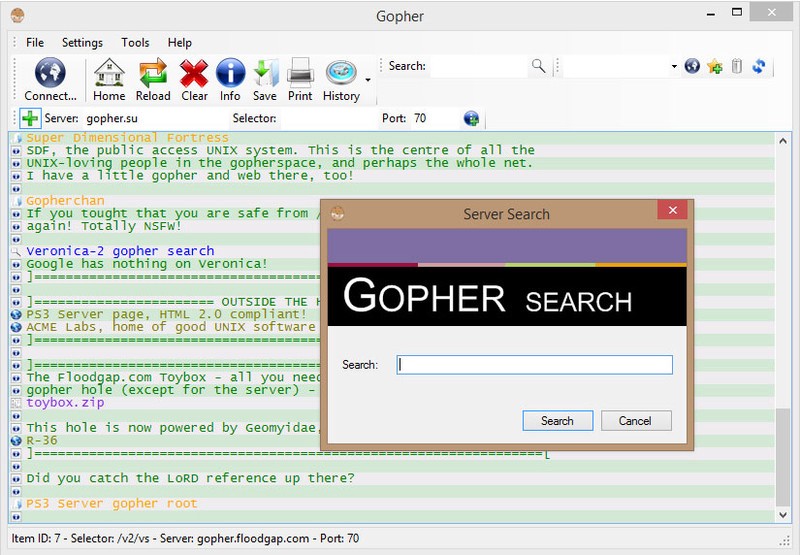
Clicking on a search link brings up the search interface–and when I search for “kittens”, Veronica returns a number of results:
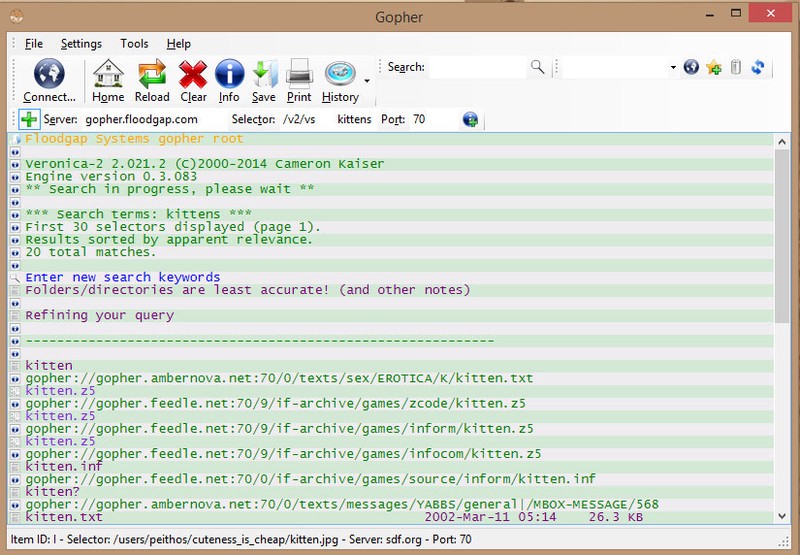
After scrolling through the list a bit, I find a link to an image of a kitten:
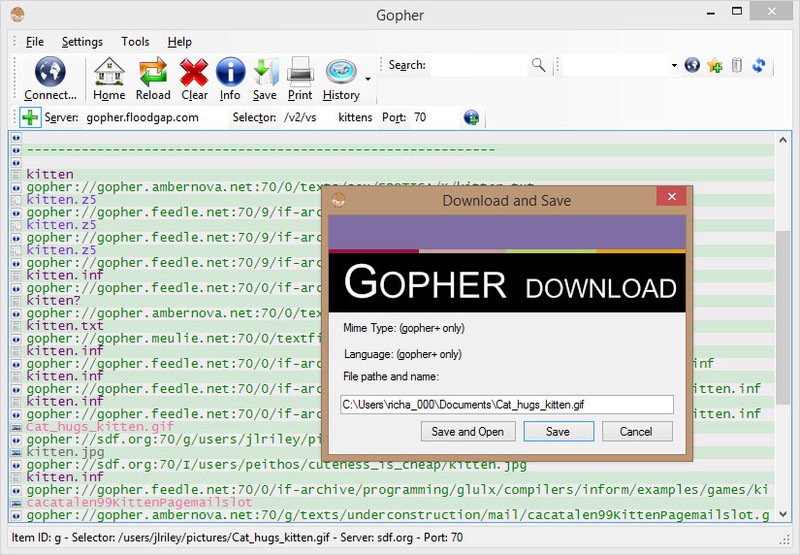
When I select this, the image downloads. It is, indeed, a picture of a kitten.
This looks like primitive stuff compared to a modern website, but we should look at it in context. Around the same time that Gopher was new, simple web browsers (like Mosaic) for accessing the web were equally awkward to use. This was heady stuff for the time, and Gopher became a popular way to share and access information, with many universities, companies, and individuals opening their own “Gopherspaces” (the Gopher equivalent of a website).
So, what went wrong? Two things: a short-sighted decision to charge for Gopher’s technology, and the increasing sophistication of HTTP and the web.
The first issue was that in 1993 the University of Minnesota decided to start charging a small fee to commercial users wishing to license the technology behind Gopher. The university argued that this was essential to fund the development of Gopher and that other software (such as the Unix operating system used on most web servers) was similarly licensed. Most users didn’t buy this argument, though, and shut down development on their Gopher systems to avoid fees. The university later relented, releasing Gopher as General Public License software in 2000, meaning that anyone could download and run it free of charge–but by then, of course, the damage was done. HTTP was on its way to becoming the standard protocol of the Internet.
HTTP has always been mostly open, allowing anyone to implement it without paying fees or acquiring licenses. It is also much more flexible–probably the main reason it won out over Gopher. Here’s how it works differently: A language called HTML (“HyperText Markup Language”) defines the way that information is structured on a web page. While Gopher only offered a short list of item types (plain text, GIF images, etc.), HTML quickly evolved to allow different types of data to exist side by side on a web page. Within a few years, we saw images, video, sound, and other data all on a single page. The development of new ways of processing data, such as Javascript, allowed the web browser to become smarter, even affording it the ability to run its own programs and pass information back to the server. All this evolved into the modern, all-singing, all-dancing web.
Gopher, by contrast, remained relatively static. Although enhancements were added that allowed for things such as images mixed with text (through an enhanced protocol called Gopher+, initially released in 1993), it remained the slower, more awkward cousin of the web. And, as makes sense, it never managed to capture the imagination of the Internet again.
But, if you’re interested in trying it out, Gopher is still available through the work of a handful of enthusiasts. The best way to dig into Gopherspaces now is through the Gopher Proxy, which allows you to access Gopher servers through a web browser. There aren’t a lot of Gopher servers still running, but there are enough to give you a feel for how it differs from the web. Try starting at the Floodgap Gopher server, which links to many of the servers still in operation.

How We Get To Next was a magazine that explored the future of science, technology, and culture from 2014 to 2019. This article is part of our The Internet section, where we report on the past, present, and future of the information superhighway. Click the logo to read more.